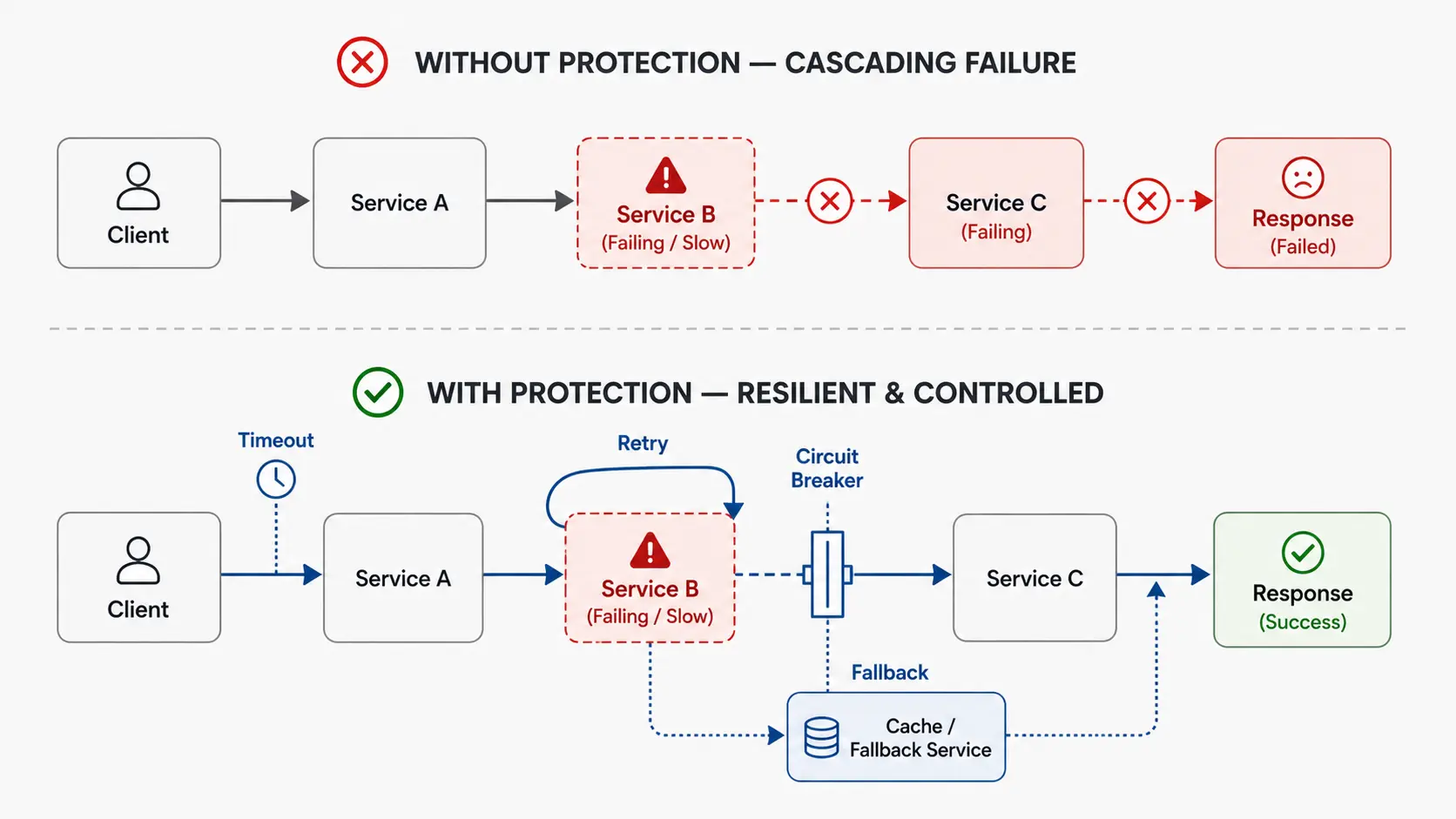
One service slows to a crawl. Requests pile up. Threads exhaust. The slowdown cascades upstream. Within minutes, the entire system grinds to a halt. This is not a hypothetical scenario—it is Tuesday afternoon in production. In microservices, failure is not an edge case. It is the default condition. The network drops packets. Services crash. Dependencies timeout. Latency spikes unpredictably. You do not prevent these failures. You design systems that survive them.
This article explains the core resilience patterns that actually work in production: timeout, retries, circuit breakers, and fallback. These are not abstract concepts. They are tactical defenses against cascading failures in distributed systems. Each pattern solves specific problems, introduces specific trade-offs, and fails in specific ways when misconfigured. Understanding how they work together is the difference between a system that degrades gracefully and one that collapses under pressure.
Why Microservices Fail Differently
Microservices introduce a failure mode that monoliths do not have: the network. In a monolithic application, a function call either succeeds or crashes the process. In microservices, a network request can fail in dozens of ways—timeout, connection refused, DNS failure, TLS handshake error, partial response, or the service simply being slow. The failure is not binary. It is probabilistic and unpredictable.
Latency is not constant. A service that responds in 50ms under normal load might take 10 seconds when a dependency is struggling. That single slow service can exhaust connection pools, block worker threads, and propagate delays upstream. One unhealthy service infects the entire call chain.
Failures cascade. Service A calls Service B, which calls Service C. If C slows down, B waits. If B waits, A waits. Now A’s callers wait. Without protection, latency propagates backward through the dependency graph, amplifying until the entire system becomes unresponsive. This is not a theoretical risk—it is how most large-scale outages unfold in practice.
Services depend on each other. In a distributed system, no service operates in isolation. Dependencies form graphs, not chains. A single service might depend on a dozen others. If any dependency fails without proper handling, the failure propagates. The system becomes as fragile as its weakest link unless you design defensive layers.
The difference between a resilient microservices architecture and a fragile one is not the absence of failures—it is the presence of deliberate boundaries that contain them.
Timeout: The First Line of Defense
Timeout is the simplest and most critical resilience pattern. It sets a hard limit on how long a client will wait for a response before giving up. Without timeout, a slow or unresponsive service can hold resources indefinitely, exhausting connection pools and worker threads.
Why timeouts matter. Imagine a service that normally responds in 100ms suddenly hangs for 60 seconds due to a database lock. Without a timeout, every incoming request holds a thread for 60 seconds. If the service receives 100 requests per second, it exhausts threads in seconds and stops processing new requests entirely. The timeout prevents this resource exhaustion by failing fast.
The timeout trade-off. Too short, and you generate false failures during legitimate slow operations—like complex queries or large file uploads. Too long, and you fail to protect against cascading latency. The timeout value must be tuned based on service behavior, not guesswork.
Setting timeout values correctly. The timeout should be slightly above the service’s 99th percentile latency under normal conditions. If your service responds in 200ms at p99, a timeout of 500ms gives headroom for variance while failing fast on true problems. Monitor actual latency percentiles and adjust accordingly.
Implementation example:
import httpx
# Set timeout to 500ms for all operations
client = httpx.Client(timeout=0.5)
try:
response = client.get("https://api.example.com/users/123")
except httpx.TimeoutException:
# Handle timeout - maybe return cached data or error
return fallback_response()
Timeout is not optional. It is the foundation of all other resilience patterns. Every network call must have an explicit timeout. Waiting forever kills systems.
Retries: Powerful but Dangerous
Retries recover from transient failures—network blips, temporary service restarts, or brief resource contention. When a request fails, the client tries again. Simple. Effective. And catastrophically destructive when implemented wrong.
Retry storms amplify load. Consider a service under heavy load that starts responding slowly. Clients timeout and retry. Now the service receives both the original requests and the retries—doubling the load. This makes the slowness worse, triggering more retries, amplifying the problem exponentially. What started as a minor latency spike becomes a full outage caused by retry traffic.
The thundering herd problem. When a service crashes and restarts, every client retries simultaneously. The service gets hammered with a massive burst of traffic the instant it comes back online, often crashing it again. This creates a failure loop where the service can never recover because retries prevent it from stabilizing.
Exponential backoff with jitter. The solution is to make retries progressively slower and randomized. Exponential backoff increases delay between retries (1s, 2s, 4s, 8s). Jitter adds randomness to prevent synchronized retries. This spreads retry load over time instead of concentrating it.
Implementation example:
import random
import time
def retry_with_backoff(func, max_retries=3):
for attempt in range(max_retries):
try:
return func()
except Exception as e:
if attempt == max_retries - 1:
raise # Final attempt failed
# Exponential backoff: 2^attempt seconds
base_delay = 2 ** attempt
# Add jitter: random value between 0 and base_delay
delay = base_delay + random.uniform(0, base_delay)
time.sleep(delay)
Retry only on idempotent operations. Never retry writes that are not idempotent. Retrying a payment charge can double-bill customers. Retrying an order placement can create duplicate orders. Only retry operations that are safe to execute multiple times, or use idempotency keys to deduplicate retries on the server side.
Retries are essential for resilience. But uncontrolled retries make outages worse. Always use exponential backoff with jitter, limit retry attempts, and never retry non-idempotent operations without safeguards.
Circuit Breaker: Stop the Bleeding
When a service is failing, continuing to call it wastes resources and prolongs the outage. The circuit breaker pattern detects failures and stops making requests to unhealthy services, giving them time to recover while protecting upstream callers.
How circuit breakers work. The circuit breaker tracks recent request outcomes. When the failure rate exceeds a threshold, the circuit “opens”—blocking all requests to the failing service and returning errors immediately. After a cooldown period, the circuit enters “half-open” state, allowing a few test requests through. If those succeed, the circuit “closes” and normal operation resumes. If they fail, the circuit opens again.
stateDiagram-v2
[*] --> Closed
Closed --> Open: Failure threshold exceeded
Open --> HalfOpen: Timeout expires
HalfOpen --> Closed: Test requests succeed
HalfOpen --> Open: Test requests fail
note right of Closed
Normal operation
Requests pass through
Tracking failures
end note
note right of Open
Fail fast
Reject all requests
Allow recovery time
end note
note right of HalfOpen
Testing recovery
Limited requests
Decide next state
end note
Protecting downstream services. The circuit breaker prevents cascading failures by stopping calls to unhealthy dependencies. Instead of waiting for timeouts or exhausting retries, upstream services fail fast and can implement fallback logic. This contains the failure to a single service instead of propagating it system-wide.
Preventing cascading failures. Without circuit breakers, every service in the call chain attempts to reach the failing service, multiplying load and extending the outage. With circuit breakers, the failure is detected once, and all upstream services immediately stop calling the unhealthy dependency.
Configuration considerations. Set the failure threshold based on expected error rate—typically 50% failures over a 10-second window. Set the cooldown period long enough for the service to actually recover—30 to 60 seconds is common. Too short, and the circuit flaps open and closed rapidly. Too long, and recovery is delayed unnecessarily.
Circuit breakers are not about avoiding failures—they are about failing fast and giving systems room to recover. The circuit breaker is the emergency shutoff valve that prevents localized failures from becoming system-wide outages.
Fallback: Graceful Degradation
When a dependency fails, returning an error to the user is often the worst option. Fallback patterns allow systems to continue operating with reduced functionality instead of complete failure. This is graceful degradation—the system remains useful even when parts are broken.
Types of fallback strategies:
- Cached data: Return the last known good response instead of failing. For product catalog or user profiles, slightly stale data is better than no data.
- Default values: Return sensible defaults when personalization services fail. Show generic recommendations instead of personalized ones.
- Partial responses: If one service fails, return data from successful services and mark missing sections. An e-commerce page can show product details even if reviews are unavailable.
- Degraded functionality: Disable non-critical features under load. Turn off real-time analytics, A/B tests, or complex personalization to reduce dependency on failing services.
Business versus technical trade-offs. Fallback decisions are not purely technical. Showing stale prices might violate business rules. Disabling fraud detection to keep checkout working is a risk decision. These choices require product and engineering alignment before incidents happen.
Implementation example:
def get_user_recommendations(user_id):
try:
# Try to get personalized recommendations
response = recommendations_service.get(user_id, timeout=0.5)
return response
except (TimeoutException, ServiceUnavailableException):
# Fallback: return cached or default recommendations
cached = cache.get(f"recommendations:{user_id}")
if cached:
return cached
# Ultimate fallback: generic popular items
return get_popular_items()
Fallback is about making intentional decisions about what matters most. Not every feature is critical. When the system is under stress, fallback patterns keep the core functionality working by sacrificing the periphery.
How These Patterns Work Together
No single pattern is sufficient. Resilient systems combine timeout, retries, circuit breakers, and fallback into defensive layers that work in sequence.
Typical request flow:
- Timeout: Client sets a 500ms timeout on the request
- Circuit breaker: Checks if the circuit is open; if so, fail immediately
- Retry: On failure, retry with exponential backoff (max 3 attempts)
- Circuit breaker: Track failure; if threshold exceeded, open circuit
- Fallback: If all retries fail, return cached data or default response
Each pattern handles different failure modes. Timeout prevents indefinite waits. Retries handle transient failures. Circuit breakers stop cascading failures. Fallback maintains functionality despite failures.
Common anti-patterns:
- Infinite retries: Retrying forever amplifies load and prevents recovery
- No timeout: Slow services exhaust resources and propagate latency
- Circuit breaker misconfiguration: Opening too aggressively causes false failures; opening too slowly allows cascading failures
- No observability: Without metrics on timeouts, retries, and circuit breaker state, you cannot tune or debug resilience patterns
Implementation libraries and tools:
- Resilience4j (Java): Comprehensive resilience library with circuit breaker, retry, rate limiter, and bulkhead patterns
- Polly (.NET): Fluent resilience and transient fault handling library
- Istio (Service Mesh): Implements timeout, retry, and circuit breaker at the infrastructure level, not application code
- Netflix Hystrix (deprecated but influential): The library that popularized circuit breakers in microservices
Implement these patterns in client libraries for consistency, or use a service mesh to enforce them uniformly across all services. The key is that every service-to-service call must have these protections.
Closing Thoughts
You do not prevent failures in distributed systems. You design systems that survive them. Timeout prevents resource exhaustion. Retries recover from transient failures—when used carefully. Circuit breakers stop cascading failures by failing fast. Fallback keeps systems useful despite broken dependencies.
The difference between fragile and resilient architecture is not the absence of failures—it is the presence of deliberate boundaries that contain them. These patterns are not theoretical. They are battle-tested defenses that have prevented countless outages in production systems. Implement them. Tune them. Monitor them. And when a service inevitably fails, your system will degrade gracefully instead of collapsing entirely.
For more on designing robust distributed systems, see our guides on API Gateway Design and Stateless vs Stateful Applications.
Questions
- Why is exponential backoff with jitter critical for retry strategies in distributed systems?
- How does a circuit breaker prevent cascading failures from propagating through a microservices call chain?