Not a very happy month for all the cloud users out there. On October 29, 2025, Microsoft Azure — the backbone of thousands of enterprise systems and consumer apps — experienced a large-scale disruption that rippled across the internet. From Office 365 to Xbox Live and even Azure’s own management portal, users worldwide faced downtime or degraded performance.
Incident Overview
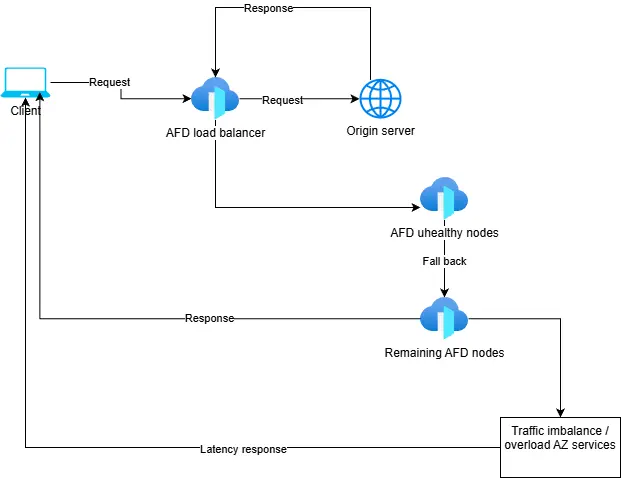
According to Microsoft’s Azure Status History, the event began at approximately 15:45 UTC on 29 October 2025 when engineers deployed a configuration change to Azure Front Door (AFD)—the service responsible for global traffic acceleration and application delivery.
The outage rippled across a wide set of services — from Azure Active Directory B2C, Azure SQL Database, and Azure Portal to Microsoft Copilot for Security and Sentinel. The cause was not a cyberattack or hardware failure, but something far more familiar in complex distributed systems: a faulty configuration change.
What happens?
As customers report high latency and connection timeouts, Microsoft’s engineering team quickly identified that the recent configuration change to AFD was the root cause. The misconfiguration led to cascading failures in routing traffic, resulting in widespread service disruptions.
An inadvertent tenant configuration deployment within AFD introduced an invalid or inconsistent configuration state. As a result, many AFD nodes failed to load properly. When unhealthy nodes dropped out, global traffic shifted unevenly to remaining nodes, which then became overloaded. The imbalance cascaded, producing intermittent availability issues across multiple regions.
This explains why even partially healthy regions saw degraded performance. As downstream services like App Service, Azure Databricks, and Azure Communication Services depend on AFD for front-end delivery, the disruption spread quickly.
Why did this happen?
The Azure team traced the root cause to a software defect in AFD’s deployment validation system. Normally, all configuration changes pass through automated safety gates designed to detect and block invalid states. In this case, a defect in the validation logic allowed the change to bypass these safeguards.
Once deployed, the invalid state propagated across part of the AFD fleet, causing nodes to fail. The incident underscores a core reality of hyperscale cloud operations: even with layered safety nets, a single defective validation path can trigger global effects.
How Microsoft responses?
Microsoft’s timeline reflects a disciplined, methodical response emphasizing containment, rollback, and phased recovery — textbook incident management for distributed systems.
| Time (UTC) | Action |
|---|---|
| 15:45 | Impact began. Monitoring alerts triggered. |
| 16:04 | Engineering teams initiated investigation. |
| 16:15 | Focus narrowed to configuration changes within AFD. |
| 16:18 | Initial public communication posted to the Azure status page. |
| 16:20 | Targeted notifications sent via Azure Service Health. |
| 17:26 | Azure Portal failed over from AFD to alternative delivery. |
| 17:30 | Microsoft blocked all new AFD configuration changes to prevent further propagation. |
| 17:40 | Began deployment of the “last known good” configuration. |
| 18:30 | Pushed the fixed configuration globally. |
| 18:45 | Started manual node recovery and gradual re-routing of traffic to healthy nodes. |
| 23:15 | Major dependent services such as PowerApps reported restored stability. |
| 00:05 | Microsoft confirmed full mitigation. |
Rather than rush a global reset, engineers executed a phased rollout. Reloading configurations and rebalancing traffic in waves reduced risk of secondary overloads as nodes came back online. This measured approach extended the timeline but prevented recurrence — a hallmark of mature incident handling.
Lessons learned
Cloud reliability is a complex, multifaceted challenge. This required not only failure detection but also on isolating, and recovering quickly when failures occur. Kudos to Microsoft for transparent communication throughout. From this incident, several key lessons emerge.
-
Rigorous validation is critical: Automated safety gates must be robust and cover all edge cases. Even a small defect can have outsized impacts in distributed systems.
-
Phased rollouts reduce risk: Gradual deployment of changes allows for monitoring and quick rollback if issues arise. This approach can prevent widespread outages.
-
Cross-service dependencies must be mapped: Understanding how services interact helps in assessing impact and coordinating recovery efforts.
-
Communication is key: Keeping customers informed during incidents builds trust and helps them manage their own responses.
-
Post-incident reviews drive improvement: Analyzing what went wrong and why is essential for preventing future incidents.