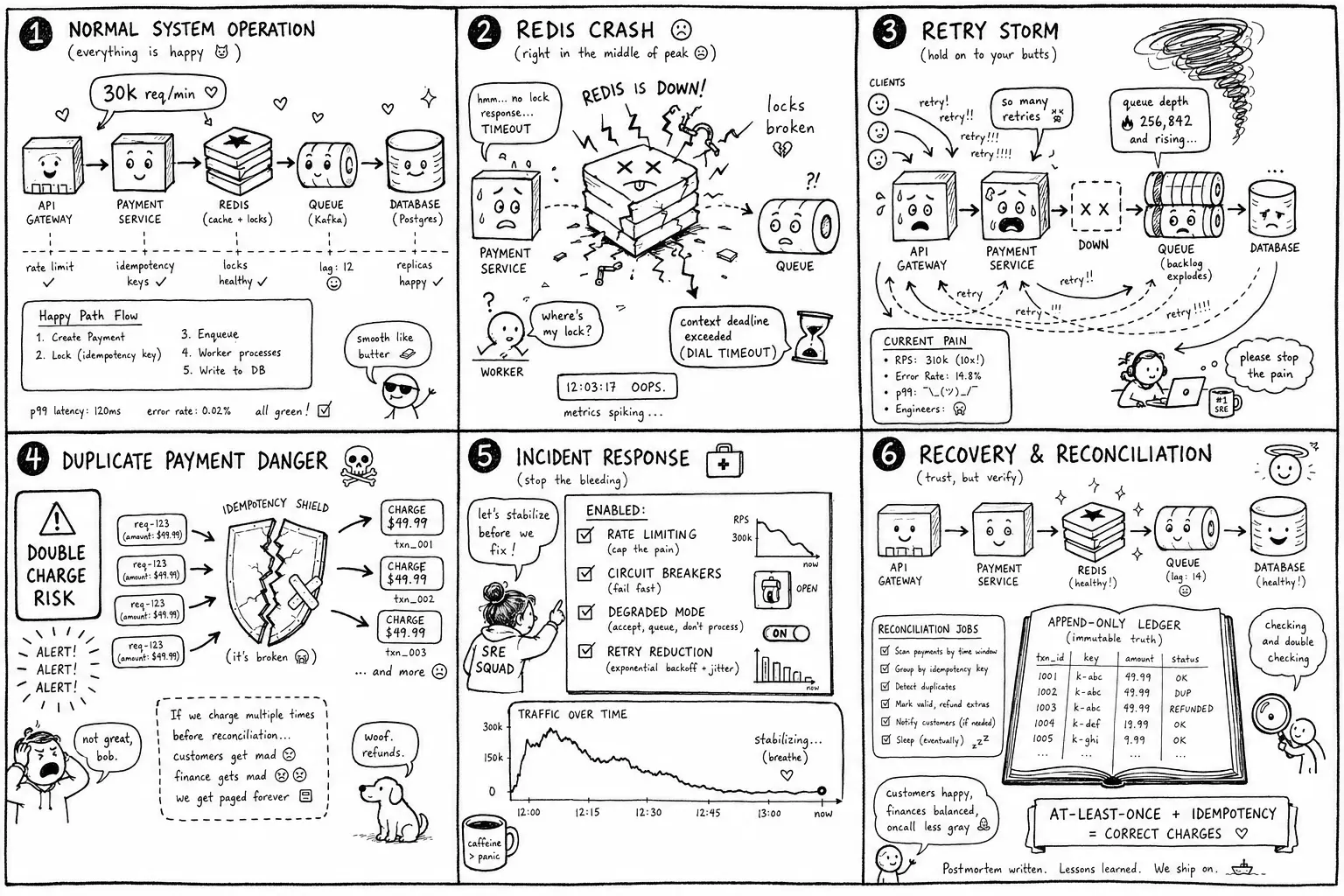
It’s peak traffic. Your payment system is processing 30,000 requests per minute. Redis dies. Within seconds, queue backlogs explode. Response times spike from 200ms to 15 seconds. Duplicate transactions start appearing in the ledger. The engineering team scrambles to understand what’s happening while customer support gets flooded with complaints. This is not a drill—it’s a real incident that happens to payment systems at scale.
The question is not whether you will face infrastructure failures. The question is whether your system survives them with financial integrity intact. This article walks through the engineering decisions that matter when critical infrastructure collapses under load, covering incident containment, consistency guarantees, recovery strategies, and architectural lessons for building payment systems that fail safely.
Typical payment system architecture with Redis:
architecture-beta group edge(logos:network-router-signal-1)[Edge Layer] group app(logos:server-api-cloud)[Application Layer] group cache(logos:cloud-storage-drive)[Cache Layer] group data(logos:database-hierarchy)[Data Layer] group external(logos:worldwide-web-network-www)[External Services] service lb(logos:network-monitor-transfer-arrow-1)[Load Balancer] in edge service api(logos:terminal)[Payment API Pool] in app service worker(logos:programming-code-idea)[Background Workers] in app service redis(logos:cloud-storage-drive)[Redis Cache] in cache service db(logos:database)[PostgreSQL Ledger] in data service queue(logos:data-transfer-horizontal)[Message Queue] in data service gateway(logos:security-shield-network)[Payment Gateway] in external lb:B --> T:api api:R --> L:redis api:B --> T:db api:R --> L:queue api:R --> L:gateway worker:L --> R:queue worker:B --> T:redis worker:B --> T:db
Blast Radius Containment — Stop the Bleeding First
When infrastructure fails during peak load, the first instinct is to fix the root cause. That instinct is wrong. The first priority is preventing system-wide collapse. A slow system beats a dead system. Financial corruption beats both.
Throttle traffic immediately. Drop the request rate by 50-70% at the edge. This is not about being fair to users—it’s about keeping the system alive. Use rate limiting aggressively. Return HTTP 503 for non-critical operations. Shed load before it reaches overwhelmed workers.
Enable circuit breakers. Stop calling Redis entirely if it’s timing out. Failing fast is better than letting requests pile up waiting for a service that won’t respond. A circuit breaker that trips in 5 seconds with a 60-second cooldown prevents retry storms from amplifying the failure.
Pause non-critical workloads. Email notifications, analytics events, recommendation updates, and settlement batch jobs can wait. Payment authorization cannot. Identify the critical path and shut down everything else. This buys time and reclaims worker capacity.
Blast radius containment architecture:
architecture-beta group edge(logos:network-router-signal-1)[Edge Defense] group critical(logos:security-shield-network)[Critical Path] group noncritical(logos:app-window-graph)[Non Critical] group storage(logos:database)[Storage] service ratelimit(logos:network-connection-locked)[Rate Limiter] in edge service circuit(logos:security-shield-wall)[Circuit Breaker] in edge service payment(logos:terminal)[Payment Service] in critical service fraud(logos:security-it-service)[Fraud Check] in critical service email(logos:worldwide-web-users)[Email Service] in noncritical service analytics(logos:analytics-graph-line-triple)[Analytics] in noncritical service db(logos:database)[Ledger DB] in storage service redis(logos:cloud-storage-drive)[Redis DOWN] in storage ratelimit:B --> T:circuit circuit:B --> T:payment circuit:B --> T:fraud payment:B --> T:db fraud:B --> T:db email:B --> T:db analytics:B --> T:db
Activate degraded mode. Define what “minimal viable payment system” looks like before the incident. Can you authorize payments without Redis? If Redis was storing sessions or rate limit counters, accept the risk and keep processing. If it was holding idempotency state, you have a harder problem—but you still need a degraded mode strategy.
The trade-off is clear: temporary service degradation versus cascading total failure. In payments, slow and correct beats fast and broken. Every second spent debugging while the system melts down is a second closer to complete outage.
Retry Storms — The Hidden Multiplier of Failure
Retries are reasonable during normal operation. During an outage, they become the primary cause of system collapse. One failed request generates three retries. A thousand failed requests generate three thousand retries. Now you have four thousand requests instead of one thousand, all failing, all retrying again.
Exponential backoff with jitter is mandatory. If a client retries immediately, it hits the same overloaded system. Exponential backoff means the first retry happens after 1 second, the second after 2 seconds, the third after 4 seconds. Jitter randomizes these intervals to prevent thundering herds. Without jitter, all clients retry at the same time, creating synchronized traffic spikes.
import random
import time
def retry_with_backoff(func, max_retries=3):
base_delay = 1.0
for attempt in range(max_retries):
try:
return func()
except Exception as e:
if attempt == max_retries - 1:
raise
# Exponential backoff: 1s, 2s, 4s
delay = base_delay * (2 ** attempt)
# Add jitter: ±30% randomization
jitter = delay * 0.3 * (random.random() - 0.5)
time.sleep(delay + jitter)
Cap retry attempts globally. A request can retry three times locally, but if the system is already overloaded, those retries make things worse. Implement a global retry budget using a shared counter. Once the system hits a threshold of failed requests (say 1000 per minute), stop all automatic retries. Force clients to back off.
Disable retries for non-idempotent operations during outages. If Redis is down and idempotency checks are failing, retrying a payment authorization risks creating duplicates. Better to return an explicit failure and let clients decide whether to retry manually with a new idempotency key.
Monitor retry rates as a primary incident metric. If retry rate exceeds 20% of total traffic, you’re in a retry storm. This is often more important than error rate. A 5% error rate with 50% retry rate means you’re processing 1.5x the normal load, all failing. The system cannot recover under those conditions.
The hard truth: during severe incidents, disabling automatic retries system-wide might be the only way to stabilize. This breaks client expectations, but it prevents complete collapse.
Idempotency — The Only Defense Against Duplicates
Payment systems must assume every request will be retried. Clients retry on timeout. Load balancers retry on connection failure. Message queues redeliver on consumer crash. Network partitions cause requests to be sent twice. The system must handle this safely.
At-least-once delivery is the reality. Exactly-once delivery is a myth in distributed systems. The network can duplicate messages. Clients can send the same request twice. Consumers can crash after processing but before acknowledging. Every payment system must accept that requests will arrive more than once and handle them correctly.
Idempotency keys are not optional. Every payment request must include a unique idempotency key—a UUID or similar identifier that uniquely identifies the intent. Two requests with the same key represent the same operation, not two separate operations.
# Client generates idempotency key once
idempotency_key = str(uuid.uuid4())
# Every retry uses the same key
response = requests.post(
'https://api.payment.com/charge',
json={
'amount': 5000,
'currency': 'USD',
'customer_id': 'cust_123',
'idempotency_key': idempotency_key
},
headers={'Idempotency-Key': idempotency_key}
)
Idempotency storage must survive failures. Storing idempotency state in Redis is dangerous. If Redis crashes, idempotency checks disappear, and duplicates become possible. Idempotency state must be stored in the same durable storage as the payment record itself—typically the relational database.
Idempotency check happens before processing. The first step of any payment operation is checking if this idempotency key has already been processed. If yes, return the previous result. If no, process the request and store both the result and the idempotency key atomically in a single database transaction.
def process_payment(request):
# Check idempotency first
existing = db.query(
"SELECT * FROM payments WHERE idempotency_key = %s",
request.idempotency_key
)
if existing:
# Already processed - return previous result
return existing.result
# Process payment and store result atomically
with db.transaction():
result = charge_customer(request)
db.execute(
"""INSERT INTO payments
(idempotency_key, customer_id, amount, status, result)
VALUES (%s, %s, %s, %s, %s)""",
request.idempotency_key, request.customer_id,
request.amount, result.status, result
)
return result
Idempotency architecture with database-backed state:
architecture-beta group client(logos:programming-browser)[Client] group fastpath(logos:cloud-storage-drive)[Fast Path] group durable(logos:database)[Durable Path] group processing(logos:terminal)[Processing] service app(logos:worldwide-web-browser)[Client App] in client service redis(logos:cloud-storage-drive)[Redis Cache] in fastpath service api(logos:server-api-cloud)[Payment API] in processing service db(logos:database)[PostgreSQL] in durable service gateway(logos:security-shield-network)[Payment Gateway] in processing app:R --> L:api api:B --> T:redis api:B --> T:db api:R --> L:gateway
Idempotency keys must have TTL. Storing every idempotency key forever is not scalable. After 24-48 hours, it’s reasonable to expire keys and allow reuse. This requires careful TTL selection based on client retry windows and reconciliation cycles.
The trade-off is storage cost versus duplicate protection window. Storing idempotency keys for 7 days provides strong protection but increases storage requirements. Storing for 24 hours is cheaper but creates a small window where very delayed retries might create duplicates. Most systems settle on 48-72 hours as a pragmatic balance.
Ledger Integrity — The Immutable Source of Truth
A payment system is not a database of balances. It is a ledger of transactions. This distinction determines whether your system can recover from failures or whether corruption spreads permanently.
Balances are computed, not stored. The naive approach stores account balances and updates them on each transaction. This creates race conditions, lost updates, and corruption during concurrent access. The correct approach stores immutable transaction records and computes balances by summing the ledger.
# WRONG: Mutating balance directly
def wrong_payment():
balance = db.query("SELECT balance FROM accounts WHERE id = %s", account_id)
new_balance = balance - amount
db.execute("UPDATE accounts SET balance = %s WHERE id = %s",
new_balance, account_id)
# Race condition: two concurrent updates lose one
# RIGHT: Append-only ledger
def correct_payment():
with db.transaction():
# Insert immutable transaction record
db.execute(
"""INSERT INTO ledger
(account_id, amount, type, timestamp, reference)
VALUES (%s, %s, %s, %s, %s)""",
account_id, -amount, 'debit', now(), payment_reference
)
# Balance is computed: SELECT SUM(amount) FROM ledger WHERE account_id = ?
Ledger architecture patterns comparison:
architecture-beta group wrong(logos:bug-browser-warning)[Mutable Balance Pattern] group right(logos:security-shield-network)[Append Only Ledger] service api1(logos:terminal)[Payment Request 1] in wrong service api2(logos:terminal)[Payment Request 2] in wrong service balance(logos:database-settings)[Account Balance] in wrong service req1(logos:terminal)[Payment Request 1] in right service req2(logos:terminal)[Payment Request 2] in right service ledger(logos:database)[Immutable Ledger] in right service computed(logos:analytics-graph-line-triple)[Computed Balance] in right api1:B --> T:balance api2:B --> T:balance req1:B --> T:ledger req2:B --> T:ledger ledger:R --> L:computed
Every financial state change is a ledger entry. Authorization, capture, refund, chargeback, fee—each is a separate immutable entry. You never update a ledger entry. You append a new entry that represents the new state. This provides complete audit history and makes reconciliation possible.
Ledger entries are never deleted. If a transaction is reversed, you create a new entry with opposite sign. This preserves the full history of what happened. During incident investigation, this history is essential for understanding what went wrong and what duplicates occurred.
Reconciliation becomes possible. With an append-only ledger, you can compare your system’s state against the payment gateway’s records, the bank’s records, and customer receipts. Mismatches are detectable and correctable because the full transaction history exists.
The architecture pattern: Redis can die, queues can lose messages, services can crash—but the ledger is the source of truth. Every payment operation must eventually write to the ledger or it did not happen.
Queue Backpressure — Prioritize What Matters
When Redis dies, queues that depend on it start backing up. Message processing slows to a crawl. Backlogs grow exponentially. Worker pools exhaust. The system chokes on work it cannot complete.
Pause low-priority consumers immediately. Not all work is equal. Email notifications, analytics events, recommendation updates, and reporting jobs can be paused without impacting payments. Stop these consumers, let their queues build up, and reclaim worker capacity for critical paths.
Implement queue prioritization. High-priority queues (payment authorization, fraud checks) get dedicated workers and process first. Low-priority queues (notifications, analytics) share workers and process only when capacity exists. During incidents, low-priority queues effectively stop processing.
Dead letter queues prevent poison messages. If a message fails five times, it moves to a dead letter queue instead of blocking the main queue. This prevents one bad message from stalling the entire pipeline. During recovery, dead letter queues are processed manually after the incident.
Backpressure signals stop upstream producers. If the queue depth exceeds thresholds (say 10,000 messages), the system should stop accepting new work. Return HTTP 503 to clients, slow down batch jobs, and let the queue drain. This is better than accepting work you cannot complete.
flowchart TD
API[API Gateway] -->|Check Queue Depth| Check{Queue > 10k?}
Check -->|Yes| Reject[Return 503
Service Unavailable]
Check -->|No| Accept[Accept Request]
Accept --> PriorityQueue[Priority Queue]
PriorityQueue --> High[High: Payments, Fraud]
PriorityQueue --> Low[Low: Email, Analytics]
High --> Workers1[Dedicated Workers]
Low --> Workers2[Shared Workers]
Workers1 --> Process[Process with
Backoff & Retry]
Workers2 --> Process
Process --> Fail{Failed 5x?}
Fail -->|Yes| DLQ[Dead Letter Queue]
Fail -->|No| Retry[Retry with Backoff]
Retry --> Process
The trade-off is completeness versus system stability. Dropping work or returning failures frustrates users. Accepting unlimited work crashes the system. During incidents, stability wins. You can process queued work later. You cannot recover from a crashed system while it’s still crashing.
Redis Failure Modes — What Breaks and Why
Redis is fast, but it is not magic. Understanding how it fails determines what breaks when it dies.
Redis usage patterns and failure impacts:
architecture-beta group cache(logos:cloud-check)[Cache Pattern Safe] group session(logos:app-window-user)[Session Pattern Annoying] group queue(logos:data-transfer-horizontal)[Queue Pattern Risky] group lock(logos:security-shield-wall)[Lock Pattern Dangerous] group idempotency(logos:bug-browser-warning)[Idempotency Pattern Catastrophic] service redis1(logos:cloud-storage-drive)[Redis Cache] in cache service db1(logos:database)[Database Fallback] in cache service redis2(logos:cloud-storage-drive)[Redis Sessions] in session service users(logos:worldwide-web-users)[Users Relogin] in session service redis3(logos:cloud-storage-drive)[Redis Queue] in queue service lost(logos:bug-browser-warning)[Lost Messages] in queue service redis4(logos:cloud-storage-drive)[Redis Locks] in lock service duplicate1(logos:bug-browser-warning)[Duplicate Processing] in lock service redis5(logos:cloud-storage-drive)[Redis Idempotency] in idempotency service duplicate2(logos:bug-browser-warning)[Duplicate Charges] in idempotency redis1:B --> T:db1 redis2:B --> T:users redis3:B --> T:lost redis4:B --> T:duplicate1 redis5:B --> T:duplicate2
Redis as cache. This is the safe use case. If Redis crashes, reads go to the database. Latency increases but the system stays correct. Cache warming after recovery is slow but manageable.
Redis as session store. Users lose sessions and must re-authenticate. Annoying but not catastrophic. The alternative is storing sessions in a database—slower but more durable.
Redis as queue. Lists used as queues (LPUSH/RPOP) lose messages on crash if persistence is disabled. If Redis is your queue, you need AOF with fsync=always or you need to accept message loss. Durable queues like Kafka or RabbitMQ are better choices for critical data.
Redis as lock coordinator. Distributed locks using SETNX and expiration are brittle. A client can acquire a lock, Redis crashes, and the lock is lost. Another client acquires the same lock. Now two clients hold the lock simultaneously. Duplicate processing occurs.
Redis as idempotency store. This is the most dangerous pattern. If Redis holds idempotency state and crashes, duplicate detection fails. Retries create duplicate charges. This is why idempotency state must be in durable storage.
Memory exhaustion is the most common failure. Redis is in-memory. When it runs out of memory, it either evicts keys (breaking logic that assumes they exist) or refuses writes (breaking systems that depend on writes succeeding). Monitoring memory usage and setting maxmemory-policy correctly is critical.
Hot keys cause CPU exhaustion. If one key receives 10,000 requests per second, a single Redis instance cannot handle it. Sharding helps but hot keys remain a problem. Distributed caching with local L1 caches can reduce hot key pressure.
Connection storms during recovery. When Redis comes back online, all clients reconnect simultaneously. This creates a thundering herd that can crash Redis again. Clients need exponential backoff with jitter on reconnection.
The architecture lesson: Redis should never be a single point of failure for financial correctness. It can fail. It will fail. Design for that reality.
Recovery and Reconciliation — Finding What Broke
Redis is back online. The system is stable. Now comes the hard part: figuring out what data is corrupted and fixing it.
Recovery and reconciliation workflow:
architecture-beta group system(logos:database-hierarchy)[Internal Systems] group external(logos:worldwide-web-network-www)[External Sources] group reconcile(logos:analytics-board-graph-line)[Reconciliation] group action(logos:programming-code-idea)[Actions] service ledger(logos:database)[Internal Ledger] in system service queues(logos:data-transfer-horizontal)[Message Queues] in system service cache(logos:cloud-storage-drive)[Cached State] in system service gateway(logos:security-shield-network)[Payment Gateway API] in external service bank(logos:security-it-service)[Bank Records] in external service compare(logos:analytics-graph-line-triple)[Comparison Engine] in reconcile service detect(logos:bug-browser-warning)[Mismatch Detection] in reconcile service refund(logos:worldwide-web-users)[Issue Refunds] in action service notify(logos:worldwide-web-users)[Notify Customers] in action service fix(logos:programming-code-idea)[Compensating Transactions] in action ledger:R --> L:compare gateway:L --> R:compare bank:L --> R:compare compare:B --> T:detect detect:B --> T:refund detect:B --> T:notify detect:B --> T:fix queues:R --> L:compare cache:R --> L:compare
Reconcile ledger against payment gateway. Query your payment gateway (Stripe, Braintree, etc.) for all transactions during the incident window. Compare against your ledger. Missing transactions were lost. Duplicate transactions need investigation—were they legitimate retries or duplicates?
Check for duplicate idempotency keys. If Redis was storing idempotency state and failed, duplicates might have been created. Query the ledger for duplicate charges to the same customer with similar timestamps. These need manual review and potential refunds.
Scan queues for stuck messages. Messages that failed during the incident might be stuck in retry loops or dead letter queues. Process dead letter queues manually with extra validation. Some messages may need to be dropped if they represent duplicate work.
Compare database state against expected state. For critical accounts, recompute balances from the ledger and compare against cached balance values. Mismatches indicate corruption that needs correction.
Notify affected customers proactively. If duplicate charges occurred, refund them immediately and notify customers. If transactions were lost, provide guidance on resubmitting. Proactive communication reduces support load and maintains trust.
Compensating transactions are better than data deletion. If a duplicate charge occurred, create a refund transaction rather than deleting the duplicate. This maintains the audit trail and explains what happened.
The reconciliation process might take hours or days depending on incident severity. During high-traffic incidents with thousands of transactions per minute, manual review becomes impractical. Automated reconciliation tooling is essential for large-scale systems.
Root Cause Analysis — Beyond “Redis Crashed”
Understanding why Redis failed determines what changes prevent recurrence.
Memory exhaustion. Check maxmemory settings, eviction policies, and key TTLs. Are keys expiring correctly? Is memory usage growing unbounded? Solution: Set maxmemory, configure eviction policy (volatile-lru for caches), and ensure all keys have appropriate TTLs.
Hot keys. Check key access patterns. Are a few keys receiving orders of magnitude more traffic? Solution: Shard hot keys, use local L1 caches, or redesign to eliminate hot key patterns.
Persistence stalls. If AOF or RDB snapshots block the main thread, Redis becomes unresponsive. Check persistence configuration and disk I/O latency. Solution: Use AOF with appendfsync everysec instead of always, or disable persistence entirely if Redis is truly a cache.
Connection exhaustion. Check connection pool configurations across clients. Are connections leaking? Solution: Set connection limits, implement connection pooling correctly, and add monitoring for connection count.
Failover instability. In Redis Cluster or Sentinel setups, failovers can cause temporary unavailability. Check failover logs and timing. Solution: Tune failover detection timeouts and ensure clients handle failover correctly.
Network partition. A network split can isolate Redis from clients while Redis itself is healthy. Check network monitoring and firewall logs. Solution: Multi-region deployments, health checks from multiple locations, and circuit breakers that trip on network issues.
Upstream thundering herd. A spike in traffic (flash sale, viral content, bot attack) overwhelms Redis capacity. Solution: Rate limiting at the edge, auto-scaling Redis capacity, and better caching architecture.
The critical insight: restarting Redis does not fix the root cause. If memory usage was growing unbounded, it will fill again. If hot keys caused CPU exhaustion, they will cause it again. Root cause analysis must drive architecture changes.
Architecture Lessons — Building Systems That Fail Safely
The incident is over. The system is stable. What changes prevent this from happening again?
Redis should not be a single point of failure. For critical paths (idempotency, distributed locks, queues), use durable storage or distributed coordination systems designed for consistency (PostgreSQL, etcd, Consul, ZooKeeper). Redis can provide performance optimization, but it should not provide correctness guarantees.
Idempotency state goes in the database. Store idempotency keys in the same transaction as the payment record. This is slower but correct. Use Redis as a fast-path cache for recent idempotency checks, but fall back to the database if Redis is unavailable.
Use durable message queues for financial data. Kafka, Pulsar, and RabbitMQ with durable queues provide at-least-once delivery guarantees that Redis cannot match. Messages survive broker restarts. This is essential for payment processing.
Design for graceful degradation. Define what the system does when dependencies fail. Can payments proceed without Redis? Without the recommendation engine? Without the analytics pipeline? Build fallback paths and degraded modes into the architecture from day one.
Stateless workers are easier to scale and recover. If workers hold state in memory, crashes lose that state. If workers are stateless and pull state from durable storage, crashes are cheap. Any worker can process any request. This simplifies recovery and scaling.
Ledger-first architecture. Every financial operation writes to the ledger before doing anything else. The ledger is the source of truth. Everything else—caches, queues, derived views—can be rebuilt from the ledger. This makes recovery deterministic.
Circuit breakers are not optional. Every dependency needs a circuit breaker with appropriate thresholds and cooldown periods. This prevents retry storms and cascading failures.
Load testing must include failure scenarios. Testing normal operation is not enough. Test what happens when Redis is down, when latency spikes to 10 seconds, when half the workers crash. These chaos engineering exercises reveal weaknesses before production incidents.
Monitoring must measure correctness, not just availability. Track duplicate transaction rates, reconciliation mismatches, and idempotency failures as first-class metrics. These indicate data integrity problems that uptime metrics miss.
The hard truth: financial systems are held to higher standards than other distributed systems. An outage is bad. Data corruption is catastrophic. The architecture must prioritize correctness over performance. Slow is survivable. Financial corruption is not.
Closing Thoughts
When Redis dies at peak load, the next sixty seconds determine whether you have a brief incident or a catastrophic outage with financial integrity problems. The difference is not luck—it’s preparation. Systems that survive these failures have blast radius containment built in. They assume retries will happen and handle them safely. They store financial state in durable ledgers, not in-memory caches. They define degraded modes before incidents, not during them.
Payment systems eventually face partial failures of every dependency. The question is whether your architecture degrades gracefully or collapses completely. This comes down to design choices made during normal operation, not heroic debugging during incidents. Every dependency must be assumed to fail. Every network call must be assumed to timeout. Every message must be assumed to arrive twice. The systems that survive are the ones designed for these realities.
Questions
-
If you store idempotency keys in Redis for performance, how do you ensure duplicate detection still works when Redis crashes during peak load?
-
Why is an append-only ledger architecture more resilient to infrastructure failures than a system that updates account balances directly?